Dec 24, 2018 原创文章
初识VGG网络模型
简述
VGG由Oxford的Visual Geometry Group提出,并取得了ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的)和定位项目的第一名。主要工作是通过设计了不同深度的网络 证明了增加网络的深度能够在一定程度上影响网络最终的性能 。
网络结构
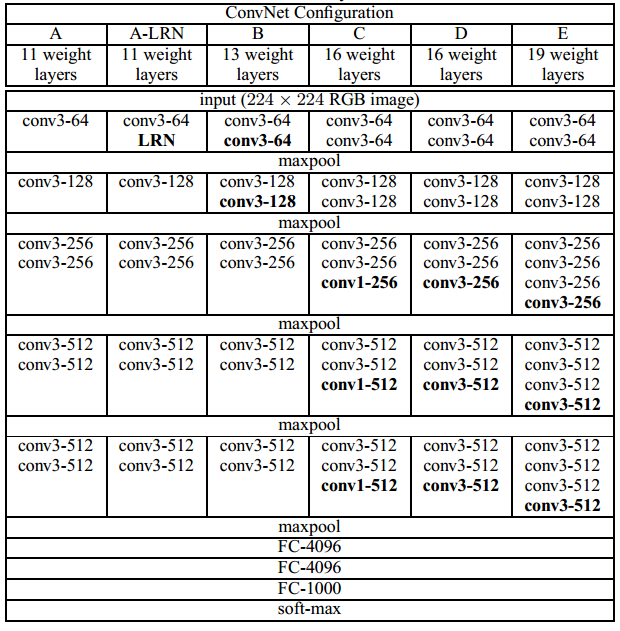
如上图所示,VGG网络共有6种不同深度的形式,每个卷积层的参数使用 conv <感知域大小>-<通道数> 表示。而每个形式的网络其通道数(即:卷积层的宽度)由64逐步增加到512。

上图总结了不同深度的VGG网络的参数数量。由此可见,随着网络深度的增加,参数的数量并不会明显的增加。
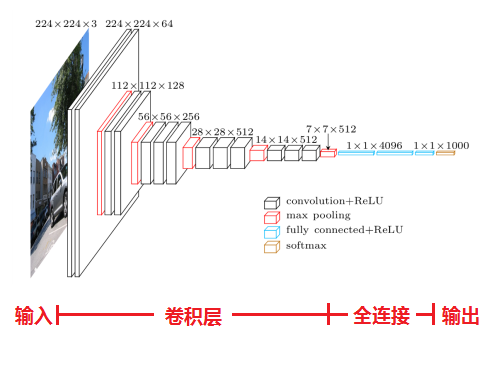
在训练过程中,网络的输入是大小为224×224的RGB图像,其预处理过程是计算每个像素的RGB均值。在VGG网络中,每个卷积层的感知域大小为3×3(这是可以捕捉中心像素上下左右信息的感知域最小值),而在VGG网络的形式C中,部分卷积层的感知域大小为1×1(表示该卷积层是对其输入的线性变换)。VGG网络的卷积层步长固定为1,而填充值的大小要使卷积后的分辨率保持不变(例如:如果感知域为3×3,则填充大小为1)。在VGG网络中空间池化选用的是maxpool层(池化窗口大小2×2,步长为2)。
在一系列卷积层之后是三个全连接层,前两个全连接层有4096个通道,而第三个全连接层则有1000个通道分别对应ILSVRC的1000个分类。而在VGG网络的最后则是一个Softmax层,用来输出分类的概率。
在VGG网络的每个隐藏层中都使用非线性激活函数ReLU。
在VGG网络的A-LRN形式中,增加了LRN(Local Response Normalisation)层,但是LRN层的增加并不会提升VGG网络在ILSVRC数据集上的表现性能,只会增加内存占用和计算时间。
网络细节
3×3卷积层的优点
在VGG网络的所有卷积层中的卷积感知域大小都为3×3、步长(stride)都为1,这样卷积层就可以与所有的输入像素进行卷积运算。
在VGG网络中将多个这样的卷积层堆叠使用具有以下的几个优点:1、具有更好辨别力。2、降低了网络参数数量。
First, we incorporate three non-linear rectification layers instead of a single one, which makes the decision function more discriminative. Second, we decrease the number of parameters: assuming that both the input and the output of a three-layer 3 × 3 convolution stack has C channels, the stack is parametrised by $3(3^2 C^2) = 27C^2$ weights; at the same time, a single 7 × 7 conv. layer would require $7^2 C2 = 49C^2$ parameters, i.e. 81% more. This can be seen as imposing a regularisation on the 7 × 7 conv. filters, forcing them to have a decomposition through the 3 × 3 filters (with non-linearity injected in between).
关于1×1卷积层的使用
在VGG网络中除了使用3×3卷积层也使用了1×1卷积层。而在网络中使用感知域大小1×1的卷积层的目的是在不影响感知域大小的情况增加决策函数的非线性。首先,感知域大小为1×1的卷积层在实质上是一个在相同维度空间(即:输入和输出具有相同的通道数)上的线性映射。其次,通过卷积层的整形函数引入了非线性变换。
网络训练、测试
网络训练
VGG网络的训练使用 具有动量的mini-batch梯度下降法(mini-batch gradient descent with momentum.)优化多项Logistic回归目标。这里 batch 的大小设置为256,动量(momentum)的大小设置为0.9。
The training was regularised by weight decay (the L2 penalty multiplier set to 5· 10−4) and dropout regularisation for the first two fully-connected layers (dropout ratio set to 0.5).
网络训练的学习率最初设定为$10^{-2}$,当 验证集的准确率 停止增长后,学习率降低为原来的十分之一。在整个训练过程中,学习率总共降低了三次,同时在经过370K次的迭代( 74 epochs)后学习的过程停止。
尽管VGG网络具有更大的网络参数数量和更深的网络层次,但是其训练过程却很简单,其原因可能如下:1、通过使用更深的网络和更小卷积核尺寸引入了 implicit regularisation 。2、VGG网络对某些层进行了预初始化。
网络权重值的初始化对于网络的训练十分重要,因为一个糟糕的初始化会由于网络中梯度的不稳定,使得学习过程变的十分艰难。为了避免这个问题,在训练网络层级较浅的VGG-A的时候采用了随机初始化。对于更深的VGG网络,则使用A型网络来初始化最前面的四个卷积层和最后三个全连接层,对于中间层则采用随机初始化方法完成网络权值的初始化。对于预初始化的层级,保持相同学习率使得其在训练过程中不断的更新。对于采用随机初始化的层级,采用均值为0方差为$10^{-2}$的随机正态分布对权重值进行随机初始化,同时其偏置值设置为0。
It is worth noting that after the paper submission we found that it is possible to initialise the weights without pre-training by using the random initialisation procedure of Glorot & Bengio (2010,Understanding the difficulty of training deep feedforward neural networks )
网络测试
网络的测试需要一个训练好的卷积网络和输入图像,并通过以下的方法实现输入图像的分类。
首先,将输入图像各向同性地缩放到预先定义的最小图像一侧,并将此标记为Q(即网络的测试尺寸 test scale),Q和网络的训练尺寸(train scale)并一定相同。然后,将网络不断的在缩放后的测试图像上应用。具体的方法是:将全连接层首先转换为卷积层(第一个全连接层转换为7×7卷积层,后两个全连接层转换为1×1卷积层),由此产生的完全卷积网络(fully-convolutional net)被用于整个未经裁剪的图像,其输出结果则是一个通道数与分类数相同,空间分辨率与输入测试图像相同的分类评分映射表(class score map)。最终,为了获得用来表示图像分类评分结果的固定大小的向量(a fixed-size vector of class scores for the image),将分类评分映射表通过 sum-Pooling 进行空间平均(spatially average)。
参考资料:
1、一文读懂VGG网络 https://zhuanlan.zhihu.com/p/41423739


