Nov 02, 2018 原创文章
Hello Pytorch 肆 -- 激活函数
激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。激活函数的使用给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
Sigmoid函数
Sigmoid函数又叫Logistic函数,是皮埃尔·弗朗索瓦·韦吕勒在1844年在研究它与人口增长的关系时命名的。广义Logistic曲线可以模仿一些情况人口增长(P)的 S 形曲线。起初阶段大致是指数增长;然后随着开始变得饱和,增加变慢;最后,达到成熟时增加停止。
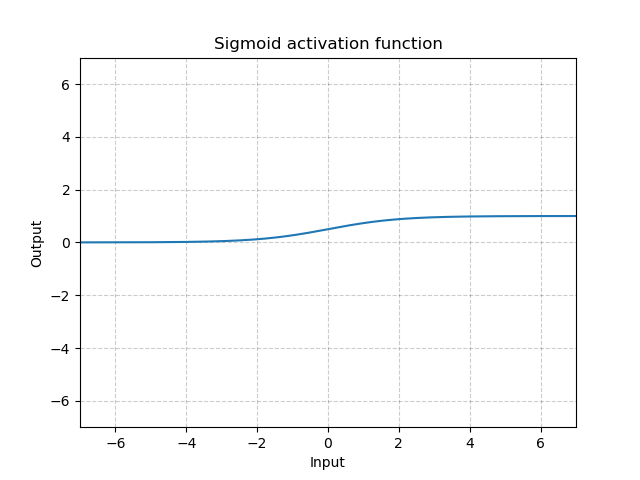
之所以叫Sigmoid,是因为函数的图像很想一个字母S。从图像上我们可以观察到一些直观的特性:函数的取值在0-1之间,且在0.5处为中心对称,并且越靠近x=0的取值斜率越大。
Sigmoid函数在物理意义上最为接近生物神经元。(0, 1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数。
计算公式:
函数图像:
Softmax函数
Softmax函数,或称归一化指数函数。用于多分类过程中将多个神经元的输出,映射到(0,1)区间内。
计算公式:
Tanh函数
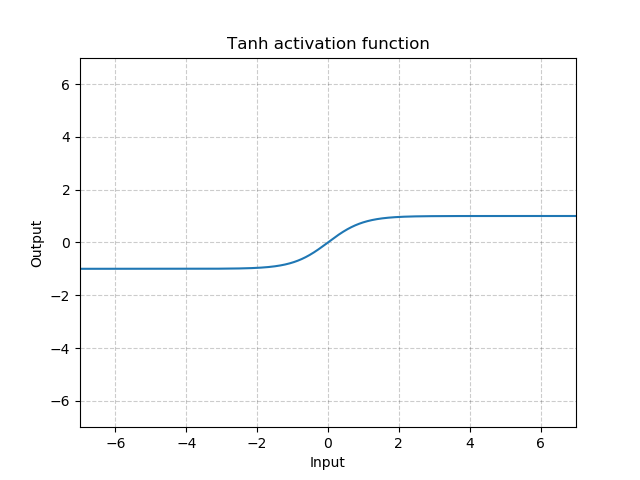
双曲正切函数(Tanh)在分类任务中用于替代Sigmoid函数以解决学习缓慢和/或梯度消失问题。
计算公式:
ReLU函数
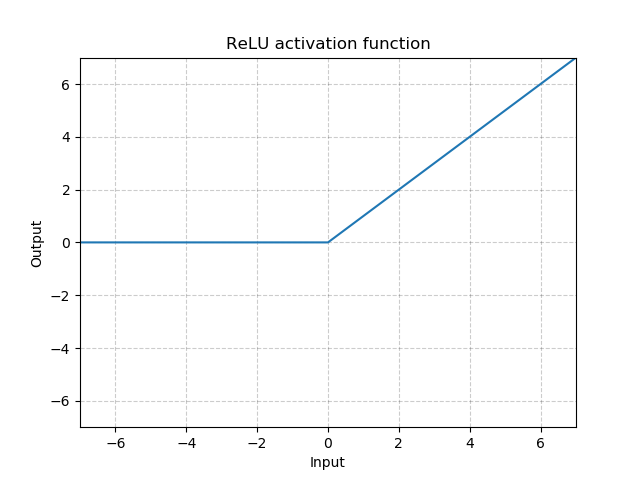
线性整流函数(Rectified Linear Unit, ReLU)其实是分段线性函数,把所有的负值都变为0,而正值不变。这种操作被成为单侧抑制,使得神经网络中的神经元也具有了稀疏激活性,在深度神经网络模型(如CNN)中,当模型增加N层之后,理论上ReLU神经元的激活率将降低2的N次方倍。
相比于其它激活函数来说,ReLU有以下优势:对于线性函数而言,ReLU的表达能力更强,尤其体现在深度网络中;而对于非线性函数而言,ReLU由于非负区间的梯度为常数,因此不存在梯度消失问题(Vanishing Gradient Problem),使得模型的收敛速度维持在一个稳定状态。
稀疏激活性:当训练一个深度分类模型的时候,和目标相关的特征往往也就那么几个,因此通过ReLU实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。
梯度消失问题:当梯度小于1时,预测值与真实值之间的误差每传播一层会衰减一次,将导致模型收敛停滞不前 (如:在深层模型中使用sigmoid作为激活函数,这种现象尤为明显)。
计算公式:
函数图像:
LeakyReLU
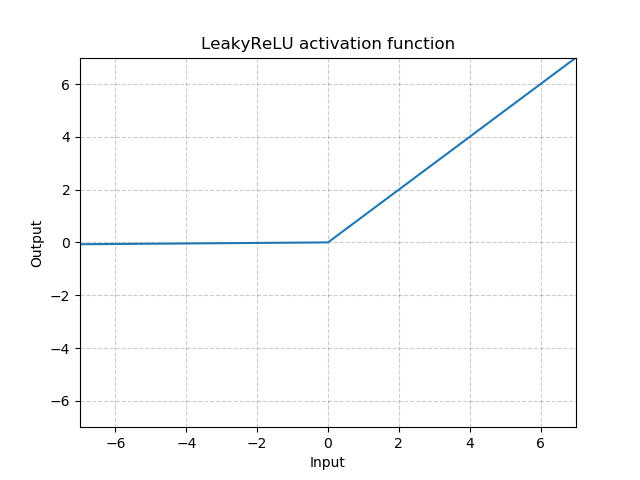
泄露线性整流函数(Leaky Rectified Linear Unit, Leaky ReLU)为ReLU激活函数的变体。其输出对负值输入有很小的坡度,因而导数总是不为零,这能减少静默神经元的出现,允许基于梯度的学习(虽然会很慢)。
计算公式:
negative_slope – 控制负值范围内的坡度的大小,默认值为1e-2。



相关文章:
Hello Pytorch 叁 -- 简单理解生成对抗网络(GAN) # 深度学习, Pytorch, 生成对抗网络, GAN Oct 29, 2018 原创文章Hello Pytorch 贰 -- 常用损失函数 # 深度学习, Pytorch, 损失函数, 交叉熵 Oct 20, 2018 原创文章
Hello Pytorch 壹 -- 卷积层原理及实现 # 深度学习, Pytorch, 卷积层 Oct 20, 2018 原创文章
Hello Pytorch 零 -- 搭建年轻人的第一个神经网络:LeNet # 深度学习, Pytorch, LeNet, CIFAR-10, CNN Oct 19, 2018 原创文章