Oct 16, 2018 原创文章
CUDA并行编程学习(6)-- 流
关于流
在GPU上,流是执行异步并行的主要载体。在GPU上,每个流都可以看作是一个独立的任务,每个流中的代码操作顺序执行。
关于CPU和GPU的异步并行详见:《CUDA并行编程学习(5)– 异步并行》
流并行
流并行是指我们可以创建多个流来执行多个任务, 但每个流都是一个需要按照顺序执行的操作队列。
页锁内存的概念
使用页锁内存的意义
想要实现流并行,需要主机使用一块固定的内存,一般称之为页锁内存(Page Locked Memory),而一般情况下经过分配得到的内存为可分页内存(Pagable Memory)。而可分页内存面临着重定位的问题,因此使用可分页内存进行复制时,复制可能执行两次操作:从可分页内存复制到一块“临时”页锁定内存,然后从页锁定内存复制到GPU。
页锁内存的性质
页锁内存 (Page Locked Memory)又称为固定内存(Pinned Memory)或者不可分页内存。 操作系统将不会对这块内存分页并交换到磁盘上,从而确保了该内存始终驻留在物理内存中,因为这块内存将不会被破坏或者重新定位。 由于gpu知道内存的物理地址,因此可以通过“直接内存访问(Direct Memory Access,DMA)” 直接在GPU和主机之间复制数据。
页锁内存的缺点
虽然在页锁定内存上执行复制操作效率比较高,但消耗物理内存更多。因此,通常对cudaMemcpy()调用的源内存或者目标内存才使用,而且使用完毕立即释放
流的运行机制
流是有序的操作序列,既包含内存复制操作,也包含核函数调用。
流的内存复制操作对应于硬件中的内存复制引擎,而函数调用则对应于硬件系统中的核函数执行引擎。而这两个引擎是彼此相互独立进行的,即我们可以在执行核函数的同时进行数据复制。所以流在复制内存时只需要向发送一个内存复制请求,即可返回到CPU中去执行其他的任务。我们不知道复制操作是否启动了,更无法保证他结束了,可以保证的是,复制操作肯定会当下一个放入流中的操作之前执行。
多个流的调度
由流的运行机制可知,流的内存复制和核函数执行是相互独立,在进行内存复制的过程中,也可以执行核函数。因此在使用多个流的时候,合理的调度是提高运行效率的关键。
设流0和流1。
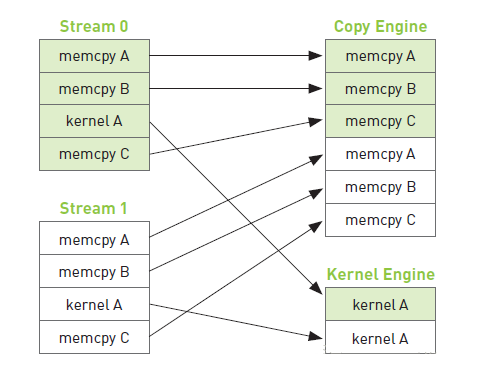
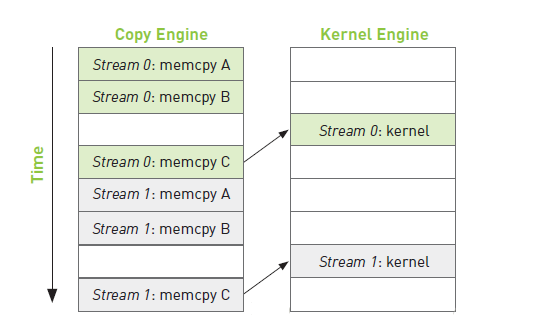
如上图所示,复制A 和 复制B 表示从主机向GPU复制数据,复制C表示从GPU向主机复制计算结果。由时间线可知,当流1的操作:复制A和复制B想要向GPU复制数据时,必须等待流0的操作:复制C执行完成,而这一操作又需要等待核函数执行完成之后才可进行。这样主机的进程就被阻塞,被迫浪费的许多运行时间。据此,可以进行如下的改进。
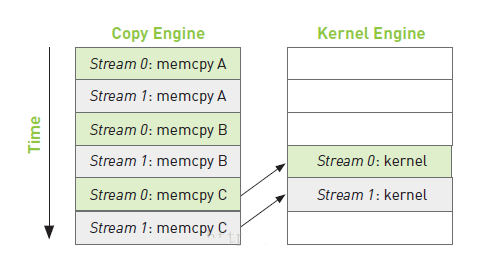
经过改进,得到了上面的时间线,在流0和流1的操作:复制A和复制B完成之后再调用核函数。这样,流1的复制A和复制B就不需要等待,节省了大量的时间,提高了运行效率。
参考资料:
1、CUDA入门(六) 异步并行执行解析: https://blog.csdn.net/qq_25819827/article/details/52541813
2、GPU 高性能编程 CUDA : 流 https://blog.csdn.net/xxiaozr/article/details/80368467
3、GPU编程自学10 —— 流并行 https://blog.csdn.net/shuzfan/article/details/77505997


